数据分区可以带来高并发,副本可以带来高可用
topic:
卡夫卡中消息存在topic中,
主题topic(半结构化):相当于数据库的表(结构化)
一般一个topic存储相同数据类型的数据,也可以存不同数据类型数据
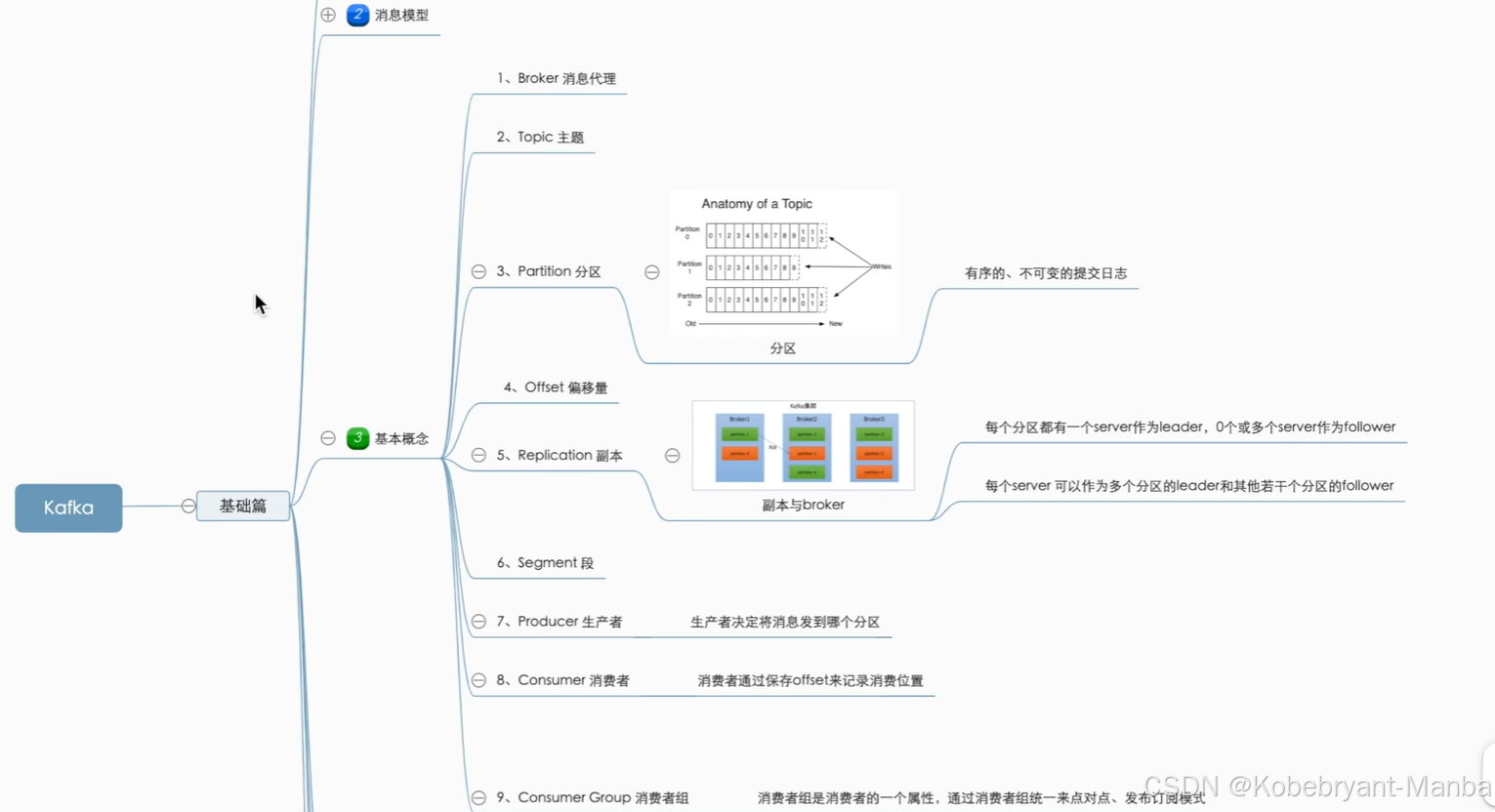
partition
topic又分为多个分区partition,不同分区分布在不同服务器上(分布式,见最后的例子),让kafka有了拓展性(通过调整分区数量和节点数量即可)
分区:线性增长、不可变的提交日志,当消息存在分区中,消息就不可变更
offset
每个分区都有一个偏移量offset:记录分区中每条消息的位置,在每个分区中唯一的、不可重复,递增的,kafka利用offset对消息进行提取,但我们没法对消息内容进行检索和查询
不同分区之间偏移量可以重复
------------
record:
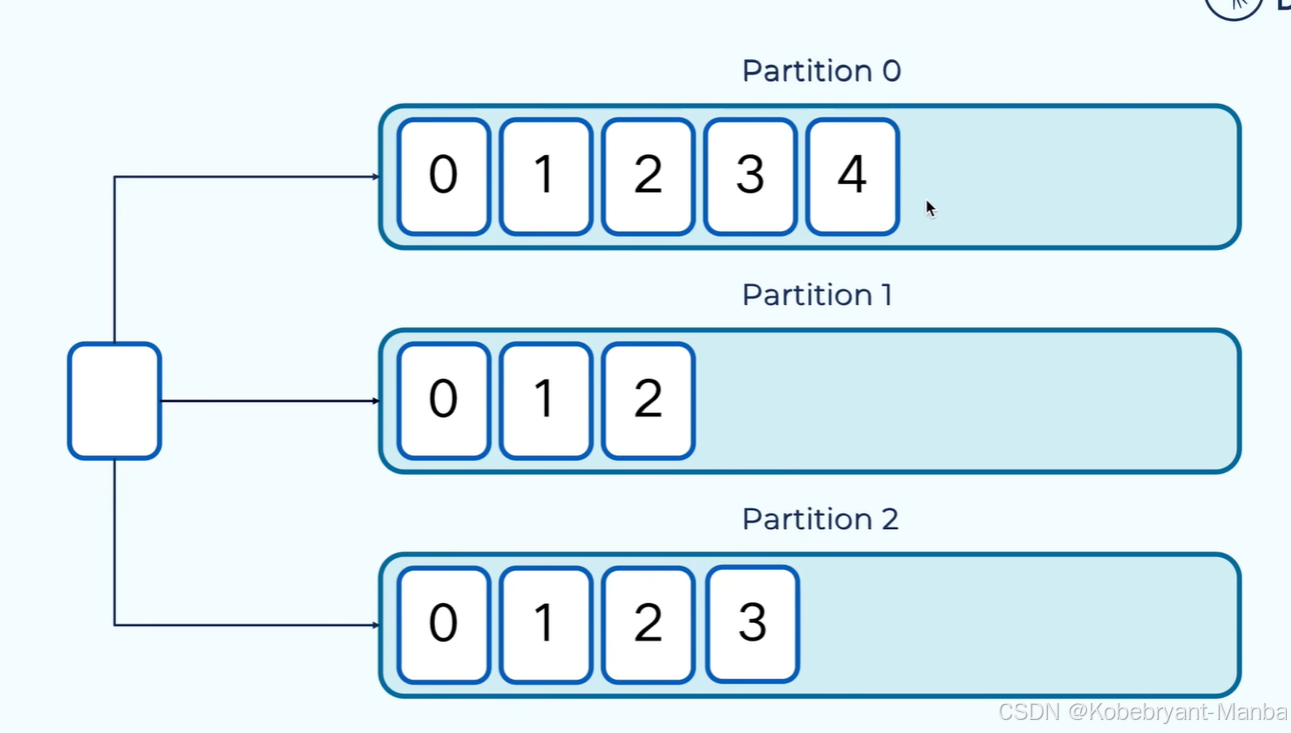
消息(记录record)是以键值对的形式进行存储 key-value:
如果不指定key,key为空,kafka就会以轮询方式写入到不同分区中:(如下)
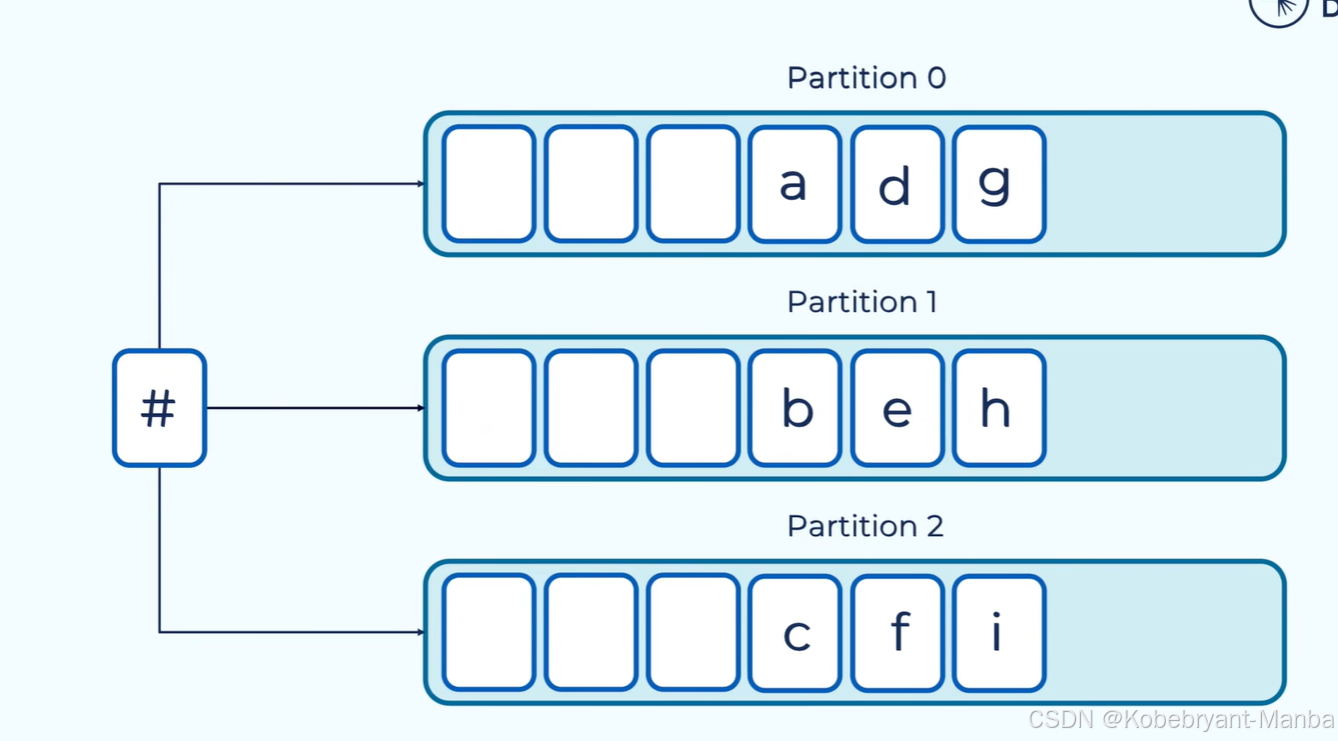
如果指定key,相同key就会写入到同一个分区:(下面以图形相同代表key相同)
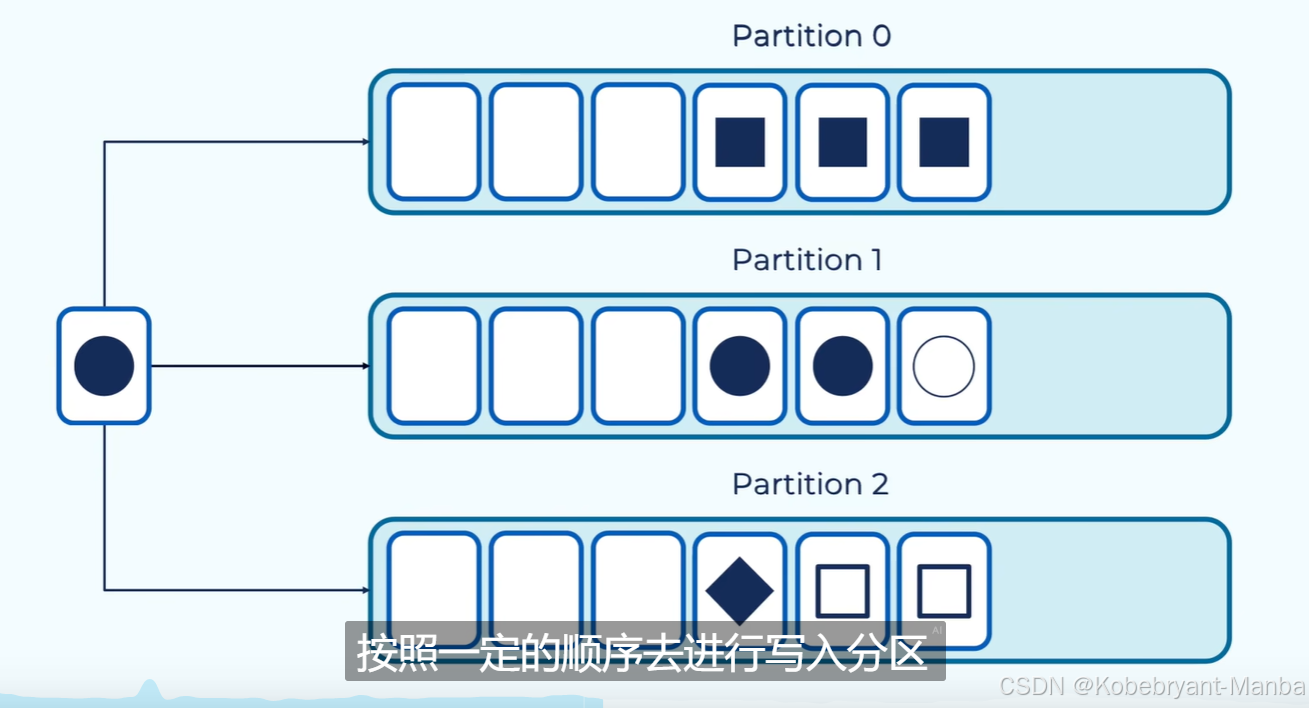
------
副本
副本replication:高可用,下图因子是3,代表包括主分区(leader)在内一共三个副本

副本就是follower,都是往主分区写入读取,然后会有一个isr副本同步集(如图包括了三个节点101 102 103),代表这三个副本正在同步,如果某一个副本落后太多,就会先从集合里面删除,等追赶上再加入
-----------
broker消息代理
:顾名思义就是负责对数据的读写请求,并将数据写入到磁盘,一般一台服务器启动一个broker实例,一台服务器就是一个broker
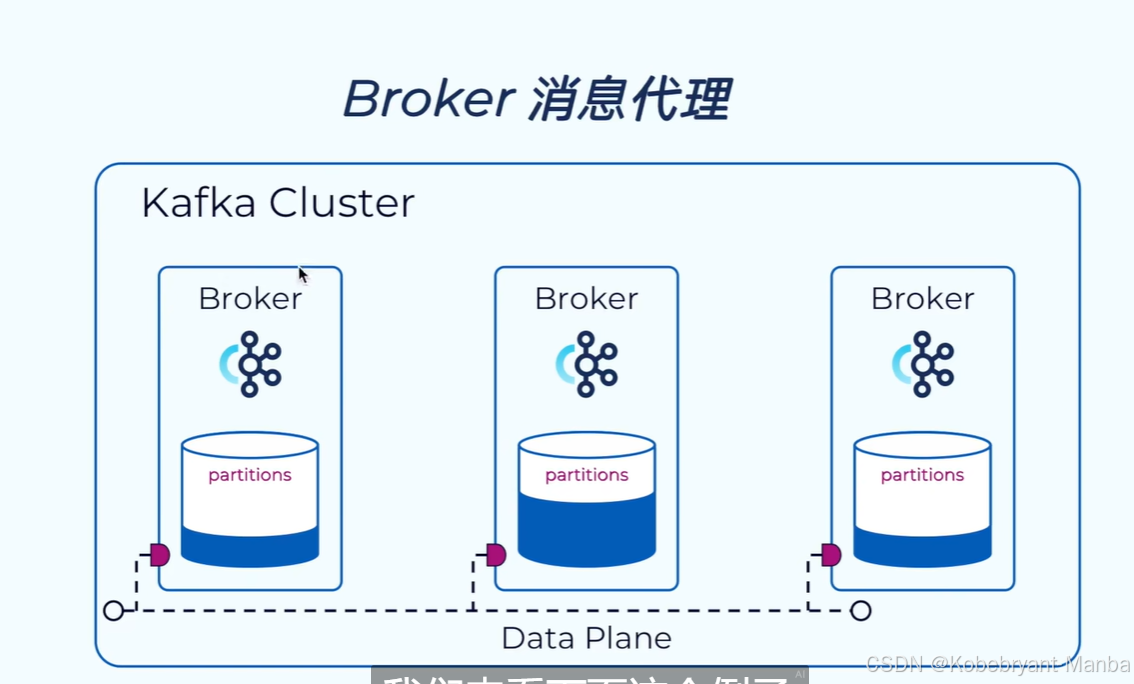
--------
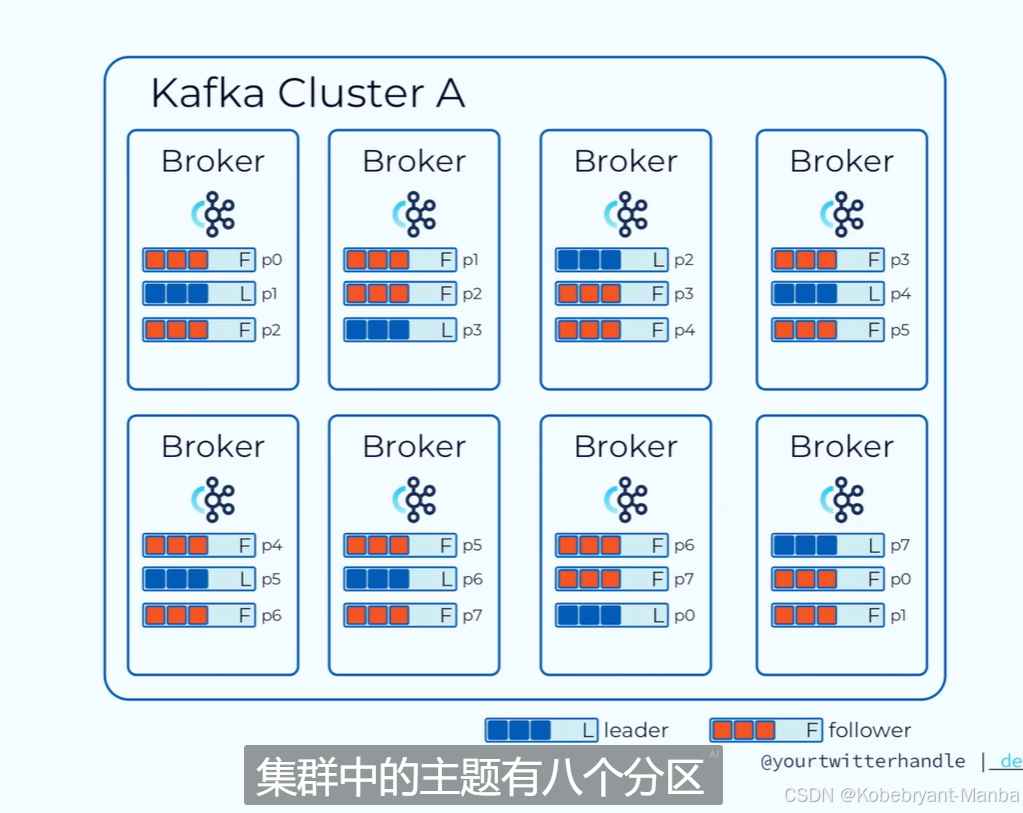
举例:
如图:一个集群有8个broker,有p0-p7一共8个分区,副本因子是3(每份数据有三份,看每个broker分区数量,每个分区都有一个leader和两个follower),比如第一个broker,p0和p2分区是follower,所以第一个broker只是负责让他们同步p1分区的数据,而对p1分区进行数据请求处理
参考:
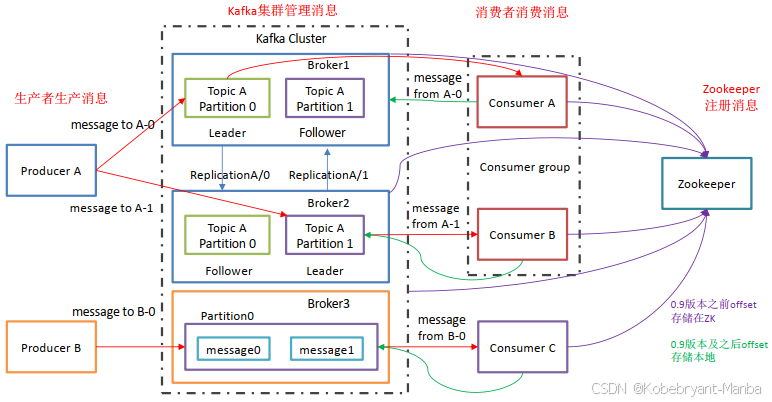
Producer:消息生产者,向Kafka中发布消息的角色。
Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
一个Topic会产生多个分区Partition,分区中分为Leader和Follower,消息一般发送到Leader,Follower通过数据的同步与Leader保持同步,消费的话也是在Leader中发生消费,如果多个消费者,则分别消费Leader和各个Follower中的消息,当Leader发生故障的时候,某个Follower会成为主节点,此时会对齐消息的偏移量。
原文链接:https://blog.csdn.net/cao1315020626/article/details/112590786