数据库中,group by 和partition by:数据分组和数据分区的区别
在大规模数据处理和分析的场景中,对数据进行分区和分组处理是非常常见的场景。
为了实现这一操作,在一些主流的关系型数据库管理系统中,提供了group by 和partition by 两个关键字。虽然他们在功能上有一些相似性,但在实际应用中却存在区别。
本文将详细探讨group by 和partition by 的差异,以及他们各自的使用场景。
一、Group by
GROUP BY用于将数据按照某个或多个列的值进行分组,然后对每个分组进行聚合操作。GROUP BY通常与聚合函数(如SUM、COUNT、AVG等)一起使用,以计算每个分组的统计结果。GROUP BY生成的结果集中,每个分组都有唯一的键值,并且可以使用HAVING子句对结果进行进一步过滤。
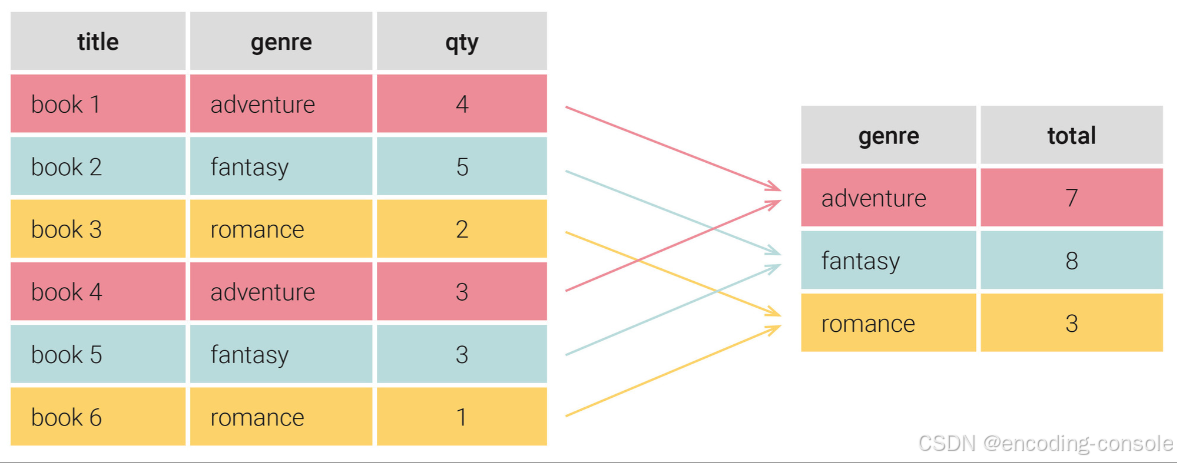
二、Partition by
Partition by 用于将表或索引的数据划分为多个分区,每个分区可以单独进行管理和操作。
Partition by 通常用于优化大型数据表的查询性能:通过将数据分散存储在不同的分区中,可以减少查询的范围。Partition by 可以按照列的值范围、列表或哈希值进行分区,提供了比较灵活的分区策略选择。画个图可能更明了些,如下:
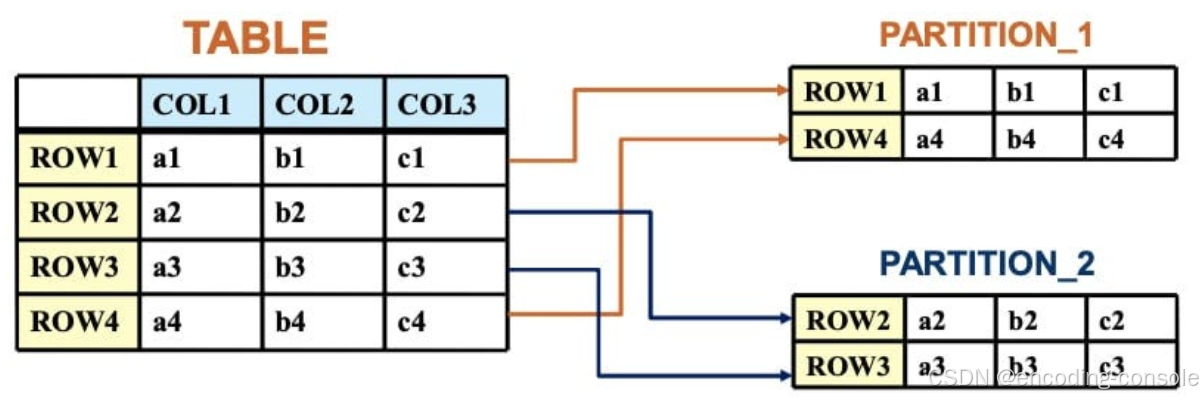
三、功能区分
- 功能不同:GROUP BY用于对数据进行分组和聚合,得到每个分组的统计结果。PARTITION
BY用于将表或索引的数据划分为多个分区,以提高查询性能。 - 数据操作层面不同:GROUP BY操作在查询结果集上进行,不会改变数据表的物理存储结构。PARTITION
BY操作在数据表或索引的存储层面进行,会改变数据的物理分布。 - 使用场景不同:GROUP BY适用于对查询结果进行分组和聚合操作,常用于统计分析、报表生成等场景。PARTITION
BY适用于大表的数据管理和查询优化,常用于分布式存储、数据仓库等场景。
四、实践
- 在使用GROUP BY时,注意选择适当的聚合函数和列进行分组,并合理使用HAVING子句进行结果过滤。
- 在使用PARTITION BY时,考虑表的大小、查询频率和数据分布等因素,选择合适的分区策略。
- 注意对分区表进行维护和管理,及时调整分区策略以适应数据的变化。
五、总结下
GROUP BY和PARTITION BY是关系型数据库中常用的关键字,用于数据的分组和分区操作。尽管它们在功能上有一定的相似性,但在实际应用中存在重要的区别。GROUP BY适用于对查询结果进行分组和聚合,常用于统计分析和报表生成等场景。PARTITION BY适用于大表的数据管理和查询优化,常用于分布式存储和数据仓库等场景。在实际使用中,我们应该根据具体需求选择合适的关键字,并结合最佳实践进行正确的数据处理和分析操作,以提高查询性能和数据管理效率。