1.FAISS是什么?
FAISS向量数据库,是来自 Meta AI(原 Facebook Research)的开源项目,也是目前最流行的、效率比较高的相似度检索方案之一。
核心功能:
- 相似性搜索:FAISS提供了多种算法来快速找到一个向量在大型数据集中的最近邻和近邻,这对于机器学习和数据挖掘任务非常有用。
- 聚类功能:除了相似性搜索外,FAISS还支持向量的聚类操作。
- 索引结构:FAISS支持多种索引结构,如HNSW(Hierarchical Navigable Small World)、IVF(Inverted Indexed Vector File)和PQ(ProductQuantization),这些结构可以针对不同的数据和查询需求进行优化。
LangChain有需要可以看看官网:
LangChain中文网:http://doc.cnlangchain.com/getting_started.html
2.开始代码实现
1.处理pdf文本
from PyPDF2 import PdfReader
# 处理文件
class PdfEngine:
# 初始化方法,用于创建对象时初始化属性
def __init__(self, url):
self.url = url
# 获取pdf文件内容
def get_pdf_text(self):
text = ""
pdf_reader = PdfReader(self.url)
for page in pdf_reader.pages:
text += page.extract_text()
return text
2.进行文本保存和加载
我这里使用的 智普的embedding-2
faisst 是文件夹名字。通过 FAISS 保存到本地,后续就不需要再执行向量化,直接读取即可
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import ZhipuAIEmbeddings
class FaissEngine:
# 保存
def save_vector_store(self,textChunks):
embeddings = ZhipuAIEmbeddings(
model="embedding-2",
api_key=""
)
print(embeddings)
db = FAISS.from_texts(textChunks, embeddings)
db.save_local('faisst')
# 加载
def load_vector_store(self):
embeddings = ZhipuAIEmbeddings(
model="embedding-2",
api_key=""
)
return FAISS.load_local('faisst', embeddings,allow_dangerous_deserialization=True)
3.配置文本处理与大模型交互
大模型交互 我使用的是 阿里的千问
from langchain.chains.conversational_retrieval.base import ConversationalRetrievalChain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
class LlmEngine():
# 拆分文本 RecursiveCharacterTextSplitter
def get_text_chunks(self,text):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
# chunk_size=768,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunks
# 获取检索型问答链
def get_qa_chain(self,vector_store):
prompt_template = """基于以下已知内容,简洁和专业的来回答用户的问题。
如果无法从中得到答案,选择默认信息
答案请使用中文,格式整洁好看一些。
已知内容:
{context}
问题:
{question}"""
prompt = PromptTemplate(template=prompt_template,
input_variables=["context", "question"])
chat = ChatOpenAI(
model="qwen-plus",
temperature=0.3,
max_tokens=200,
api_key="",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
return RetrievalQA.from_llm(llm=chat, retriever=vector_store.as_retriever(),
prompt=prompt)
def get_qa_chain_history(self, vector_store):
prompt_template = """基于以下已知内容,简洁和专业的来回答用户的问题。
如果无法从中得到答案,请大模型进行处理。
答案请使用中文。
已知内容:
{context}
问题:
{question}"""
prompt = PromptTemplate(template=prompt_template,
input_variables=["context", "question"])
chat = ChatOpenAI(
model="qwen-plus",
temperature=0.3,
max_tokens=200,
api_key="",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
return ConversationalRetrievalChain.from_llm(llm=chat, retriever=vector_store.as_retriever(),
combine_docs_chain_kwargs={'prompt': prompt})
4.测试向量,生成知识库
import os
from faisst.FaissEngine import FaissEngine
from faisst.LlmEngine import LlmEngine
from faisst.PdfEngine import PdfEngine
# 将pdf切分块,嵌入和向量存储
if __name__ == '__main__':
#将pdf切分块
current_dir = os.path.dirname(__file__)
print(current_dir+"/demo.pdf")
pfdEngine = PdfEngine(current_dir+"/demo.pdf")
raw_text = pfdEngine.get_pdf_text()
#拆分文本
llmEngine = LlmEngine()
text_chunks = llmEngine.get_text_chunks(raw_text)
#faisst分析 我这里使用的是智普
faissEngine = FaissEngine()
faissEngine.save_vector_store(text_chunks)
print(current_dir + ' is ok')
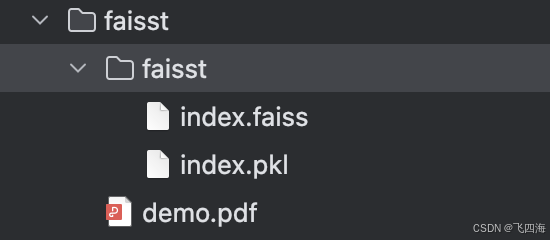
最后是这样的
5.测试与大模型对话匹配
from faisst.FaissEngine import FaissEngine
from faisst.LlmEngine import LlmEngine
if __name__ == '__main__':
# 加载 处理后的知识库
faiss = FaissEngine()
vector_store = faiss.load_vector_store()
# 将匹配的知识库和用户问题进行匹配 交给大模型分析
llm = LlmEngine()
chain = llm.get_qa_chain(vector_store)
# 支持历史模型 可以自己实现保存到数组 每次都带着上一次信息
chat_history_tuples = []
# response = chain.invoke({"question": "百度都有什么大模型?", "chat_history": chat_history_tuples})
# 单个对话请求
response = chain.invoke({"query": "我有想做系统有400万辆车,帮我出一个架构"})
print(response)
我的分析内容:

最后返回结果,还是比较准确的,大模型也帮我美化了一下:
{‘query’: ‘我有想做系统有400万辆车,帮我出一个架构’, ‘result’: ‘根据您提供的信息,针对拥有400万辆车的系统,建议采用与“系统2”相似的架构。以下是推荐的系统架构配置:\n\n### 系统架构配置:\n- 系统ID:bbbbbb 或 cccccccccc(根据具体需求选择)\n- 车辆数量范围:400-600万辆\n- 所需产品:\n - API网关\n - ECP(企业级通信平台)\n - OSS(对象存储服务)\n - Kafka(分布式流处理平台)\n - Mysql(关系型数据库)\n\n### 架构说明:\n1. API网关:用于统一管理和控制所有外部和内部API的访问,确保系统的安全性和高效性。\n2. ECP:提供稳定的企业级通信支持,保障车辆与后台系统之间的数据传输。\n3. OSS:用于存储大量的非结构化数据,如车辆图片、视频等。\n4. Kafka:实现高效的实时数据流处理,适用于大规模车辆数据的采集和分析。\n5. Mysql:作为关系型数据库,用于存储和管理结构化的车辆及用户信息。\n\n此架构能够满足400万辆车的数据处理和业务需求,确保系统的高性能和稳定性。如果您有更多定制化需求,请进一步咨询。’}
6.整体结构