Scrapy数据解析+保存数据
目录
1.数据解析
2.基于item存放数据并提交给管道
3.用txt文件来保存数据
今天我们需要爬取B站数据并保存到txt文件里面。
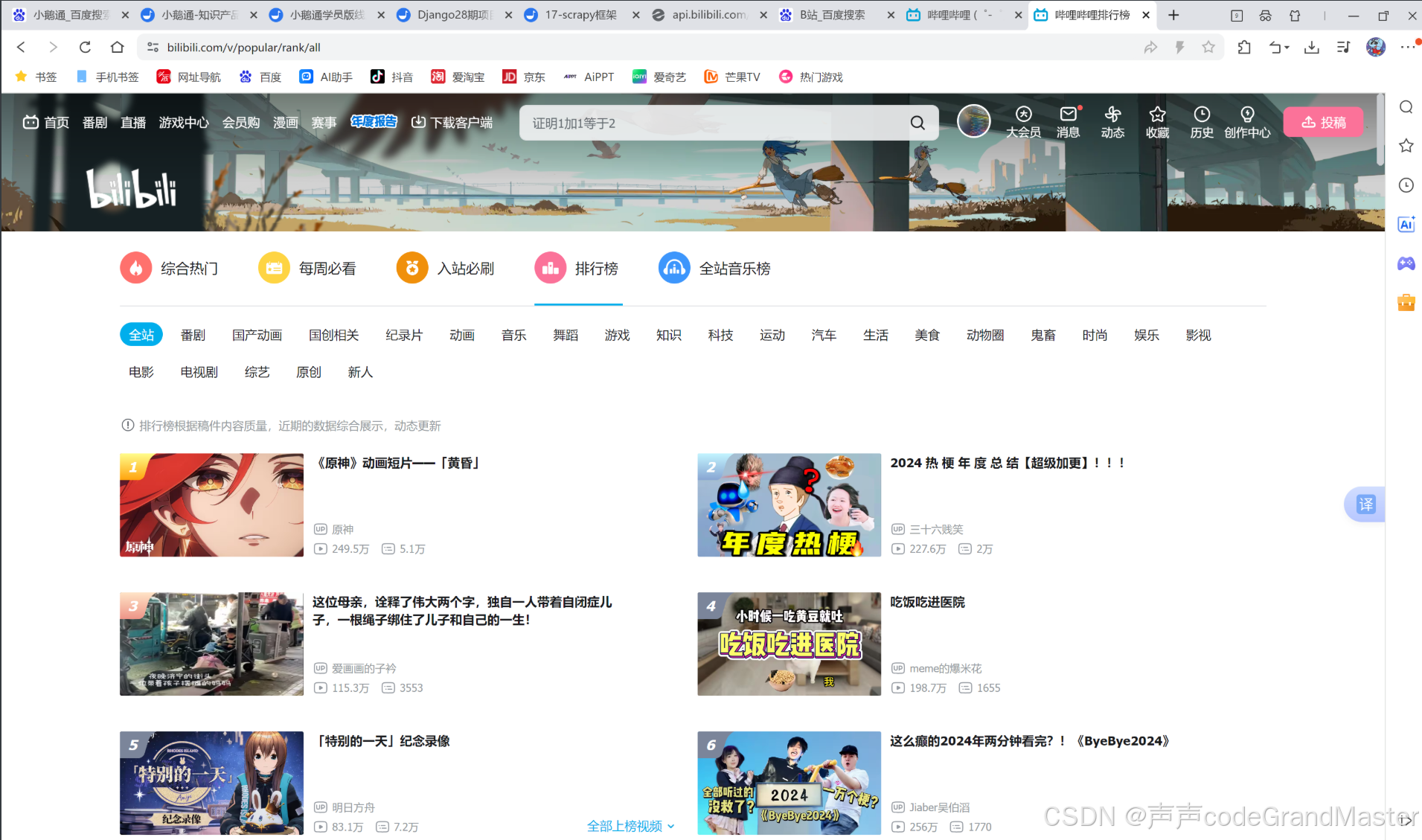
我们先打开B站, 然后点击热门, 进去之后再点击排行榜:
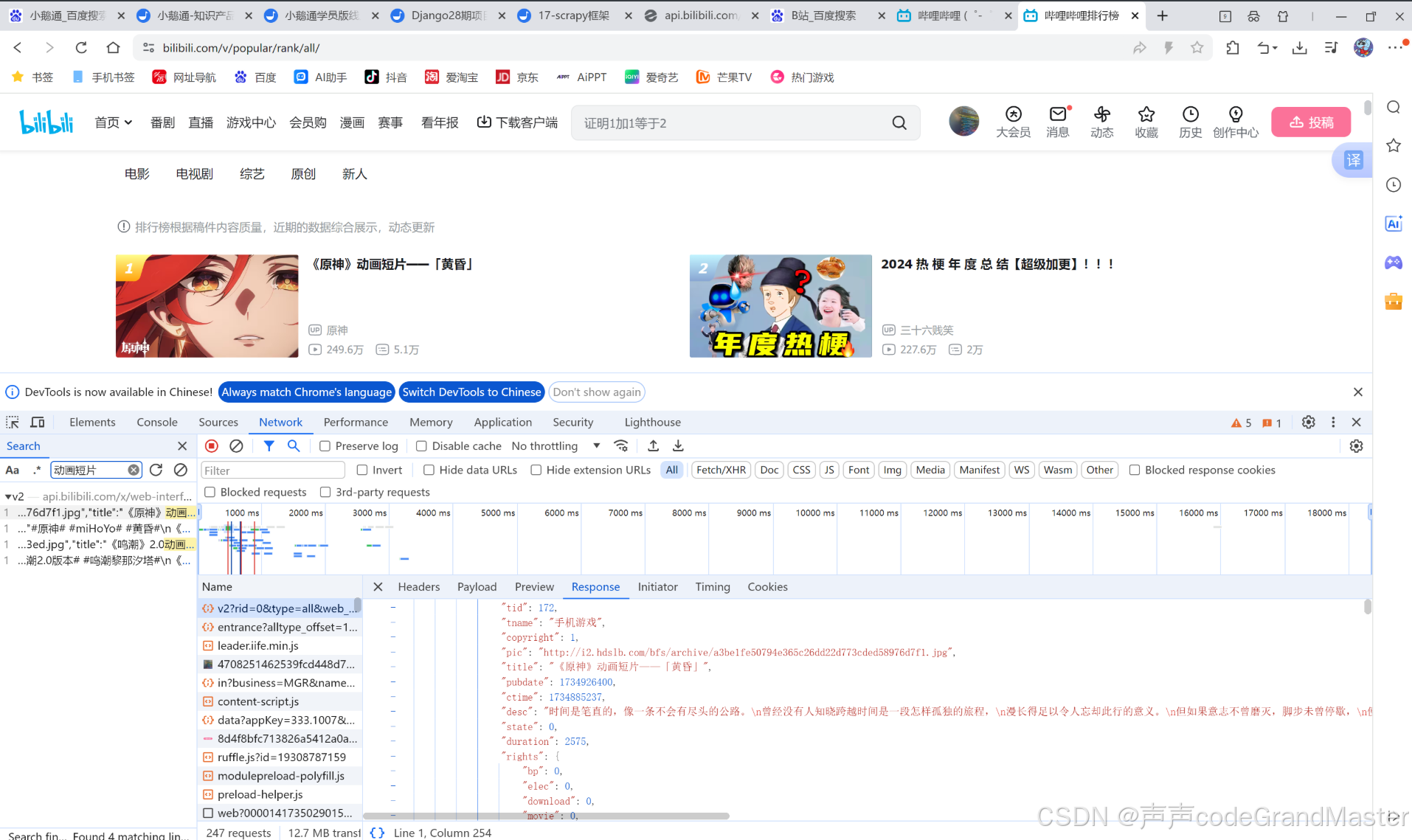
我们打开F12后, 可以看到, 我们想要的请求, 轻而易举的就可以拿到(通过搜索关键字功能)。
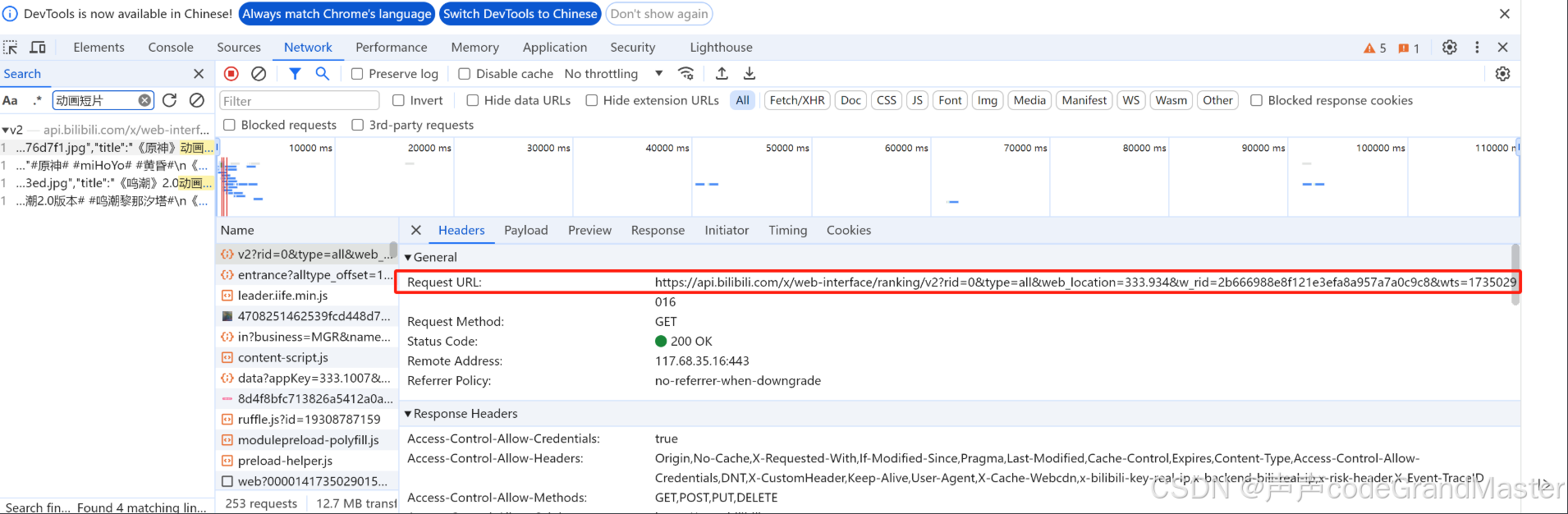
一、数据解析
首先, 我们需要把我们想要解析数据的请求, 放到start_urls里面:
start_urls = ["https://api.bilibili.com/x/web-interface/popular?ps=20&pn=1&web_location=333.934&w_rid=c78bd05ec31e04bcaa0689863761dd73&wts=1730296798"]
然后开始数据解析, 数据解析的方法, 之前爬虫文章已经讲到过, 并且还有大量的实战, 所以这里不再赘述, 直接上代码。
数据解析对应的代码:
def parse(self, response):
data = response.json()
for i in data['data']['list']:
# 视频id
bvid = i['bvid']
# 视频作者
name = i['owner']['name']
# 视频标题
title = i['title']
# 视频描述
desc = i['desc']
# 播放数
stat = i['stat']['view']
print(bvid, name, title, desc, stat)
我们再parse里面写解析代码, 不过跟之前不一样的是, 不需要写url再发request请求之类的代码了, 因为我们用的是scrapy框架, 我们只需要直接用response.json()这样就可以解析json格式的数据, 而且response里面的数据, 就是我们在start_urls那个列表里面的请求出来的数据。
运行:
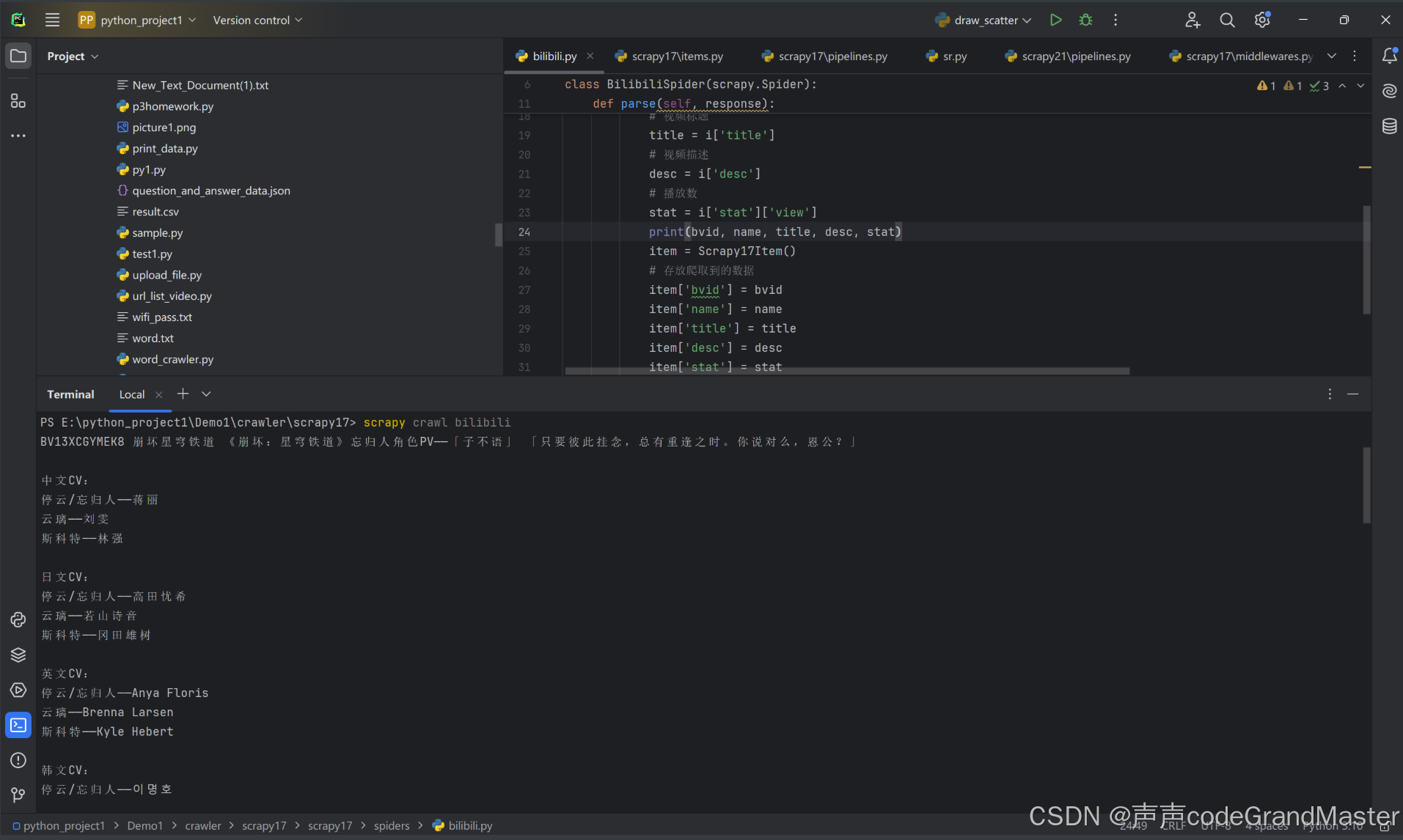
我们已经成功的爬到数据了。
二、基于item存放数据并提交给管道
我们需要编辑items.py
items.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Scrapy17Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
bvid = scrapy.Field()
name = scrapy.Field()
title = scrapy.Field()
desc = scrapy.Field()
stat = scrapy.Field()
把我们所有要用到的字段, 全部写进来, 写法是变量名=scrapy.Field()
然后再parse函数里面在接着写代码:
import scrapy
from scrapy17.items import Scrapy17Item
class BilibiliSpider(scrapy.Spider):
name = "bilibili"
# allowed_domains = ["bilibili.com"]
start_urls = ["https://api.bilibili.com/x/web-interface/popular?ps=20&pn=1&web_location=333.934&w_rid=c78bd05ec31e04bcaa0689863761dd73&wts=1730296798"]
def parse(self, response):
data = response.json()
for i in data['data']['list']:
# 视频id
bvid = i['bvid']
# 视频作者
name = i['owner']['name']
# 视频标题
title = i['title']
# 视频描述
desc = i['desc']
# 播放数
stat = i['stat']['view']
print(bvid, name, title, desc, stat)
item = Scrapy17Item()
# 存放爬取到的数据
item['bvid'] = bvid
item['name'] = name
item['title'] = title
item['desc'] = desc
item['stat'] = stat
# 提交item
yield item
这里我们用刚才写好的Scrapy17Item, 把我们爬取到的数据先存到item里面, 这里用yield提交item数据, 为了之后保存数据做铺垫。
三、基于管道来保存数据
上面我们已经做好了铺垫, 那接下来我们就要对数据进行保存。
我们打开pipelines.py文件:
输入相应代码:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class Scrapy17Pipeline:
def open_spider(self, spider):
self.f = open("数据.txt", "a", encoding="utf-8")
def process_item(self, item, spider):
# print("管道内中的process_item执行了", item)
self.f.write(str("视频id号:" + item['bvid'] + ",视频作者:" + item['name'] + ",视频描述:" + item['desc'] + ",播放数:" + str(item['stat']) + "\n"))
return item
def close_spider(self, spider):
self.f.close()
在pipe管道类里面有三个函数, 我们在open_spider函数里面创建文件, process_item里面的内容就是我们上面做好的铺垫拿到这里用, 把我们之前提交好的管道item写入, 在此函数里面使用item, 然后就可以用item[‘参数名’]这种方法给它获取我们之前爬虫获取的值, 最后不要忘记return item。最后我们在close_spider函数里面关闭文件资源。
运行结果:
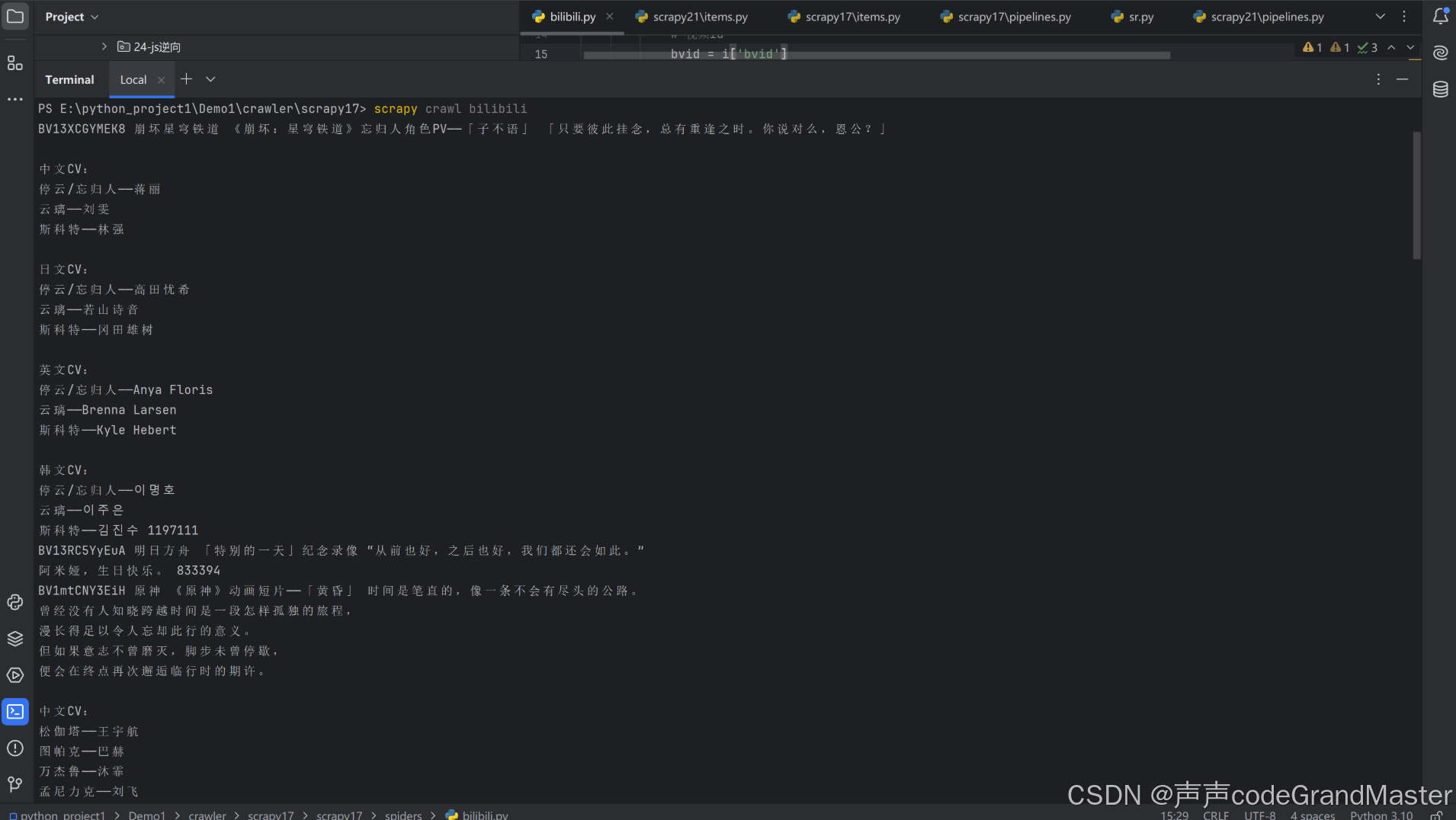
打开txt文件:
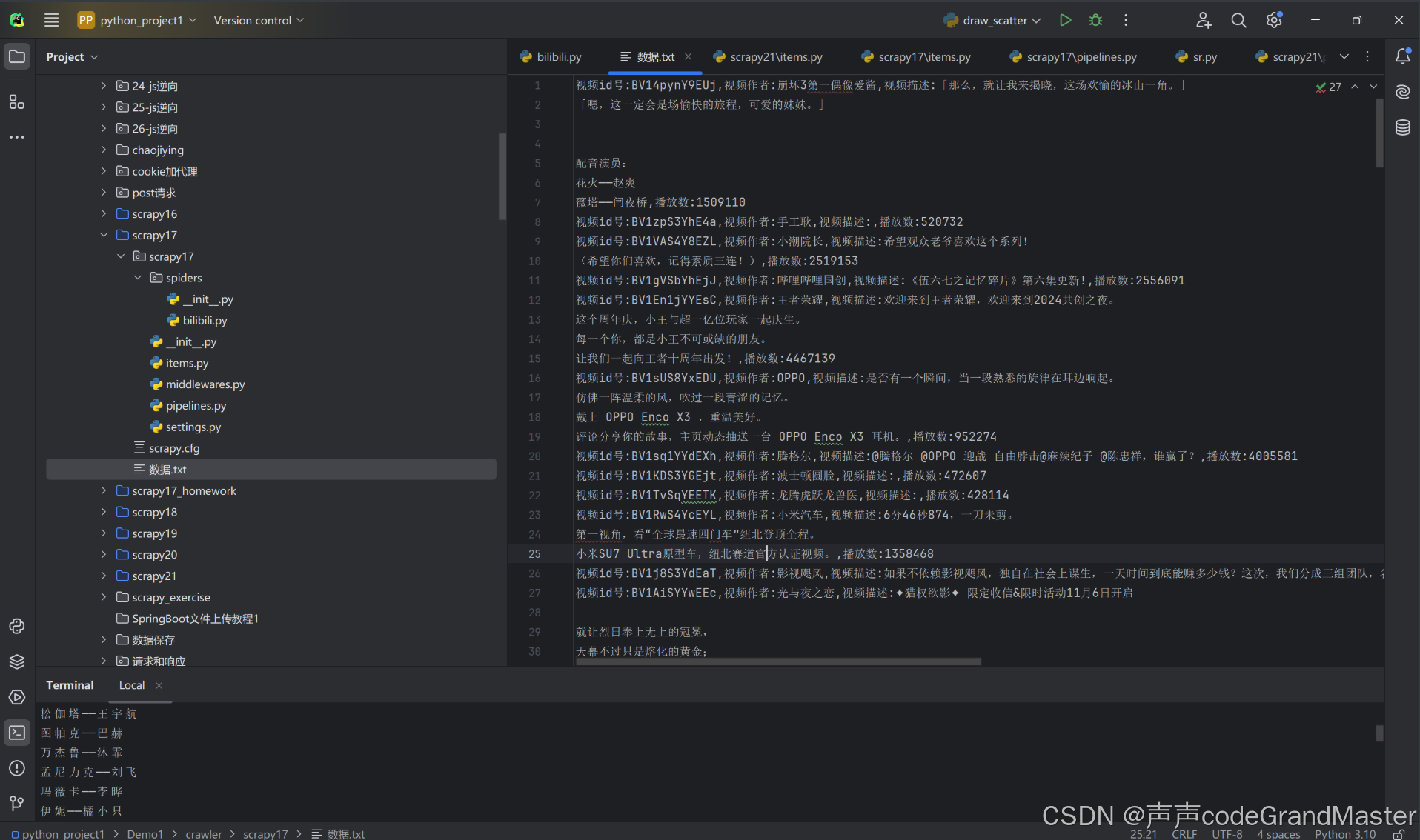
我们成功把B站的数据爬取并保存到txt文件。
创建scrapy和运行scrapy命令是上一篇文章所讲的, 如果大家对这个还不熟悉的话, 可以翻一翻上一篇文章的内容, 包括settings.py里面需要配置的细节内容, 也需要参考上一篇文章(如果settings.py配置文件里面的内容, 有新的东西要配置, 肯定会在文章中写出来, 如果文章中没有写关于settings.py配置的代码, 那就默认安装scrapy框架的第一篇文章里面的内容来配置)。
以上就是Scrapy数据解析+保存数据的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越来越大.
人生路漫漫, 白鹭常相伴!!!